검색결과 리스트
분류 전체보기에 해당되는 글 782건
- 2023.11.01 리커트(Likert) 척도는 서열척도인가?
- 2023.11.01 측도와 척도
- 2023.11.01 표본이 정규분포(정규성)인지 여부를 어떻게 알 수 있는가? 1
- 2023.11.01 평균 추론에 필요한 조건
- 2023.11.01 왜 유의확률(p value)은 0.05를 기준으로 하는가?
글
리커트(Likert) 척도는 서열척도인가?
사회조사 논문을 보면 리커트 척도를 등간척도로 다루어 상관분석과 회귀분석을 해 놓은 것을 많이 볼 수 있다. 하지만 뭔가 이상하지 않은가? 분명 배운대로라면 리커트 척도는 서열척도가 맞다. 이에 대한 논쟁은 과거부터 꾸준히 있어왔던 듯하다. 이에 대해 잘 정리한 논문이 있어 한편 소개한다.
바로 후이핑 우(Huiping Wu)와 싱온 렁(Shing-On Leung)이 2017년 Journal of Social Service Research에 기고한 "Can Likert Scales be Treated as Interval Scales? - A Simulation Study"이다. 이 연구의 Introduction을 보면, Jamieson(제이미슨, 2004)을 비롯한 인용해 엄밀히 말해 서열척도인건 분명하다고 본다. 한편 척도를 만들어낸 Stevens(스티븐스, 1946) 또한 서열척도를 등간척도로 다루었을 때의 유용성에 동의했다며, 리커트 척도의 개수를 늘려간다면 연속적인 척도로 보아 산술연산을 하는 것도 가능하다는 입장도 소개한다. 또한 Borgatta(보가타) & Bohrnstedt(보른스테드)는 리커트 척도를 불완전한 등간척도라 부르기도 한다.
서열척도를 등간척도로 다루는 것은 기본 가정을 위반한다는 문제점에도 불구하고 그 실효성이 높다는 딜레마를 안고 있다. 이 논문의 저자들은 그렇다면 얼마나 리커트 척도를 늘려가야 등간척도와 유사한 결과를 얻을 수 있는지에 대해 실험하고 그 결과 0~10까지 11점 척도가 된다면 등간척도로 보아도 무방한 결과를 도출한다고 결론내리고 있다.
'[楞嚴] 생각 나누기 > [平] 사회조사와 데이터분석' 카테고리의 다른 글
| 알아두면 쓸모있는 통계관련 잡학상식 (0) | 2023.12.11 |
|---|---|
| 표본오차(sampling error) (2) | 2023.11.01 |
| 측도와 척도 (0) | 2023.11.01 |
| 표본이 정규분포(정규성)인지 여부를 어떻게 알 수 있는가? (1) | 2023.11.01 |
| 평균 추론에 필요한 조건 (0) | 2023.11.01 |
설정
트랙백
댓글
글
측도와 척도
일반적으로 변수(variable)의 속성으로 구분한 기준을 말하는 것은 척도(scale)이다. 한편 변수를 측정한 값은 측도(measure)라 한다.

'[楞嚴] 생각 나누기 > [平] 사회조사와 데이터분석' 카테고리의 다른 글
| 표본오차(sampling error) (2) | 2023.11.01 |
|---|---|
| 리커트(Likert) 척도는 서열척도인가? (0) | 2023.11.01 |
| 표본이 정규분포(정규성)인지 여부를 어떻게 알 수 있는가? (1) | 2023.11.01 |
| 평균 추론에 필요한 조건 (0) | 2023.11.01 |
| 왜 유의확률(p value)은 0.05를 기준으로 하는가? (0) | 2023.11.01 |
설정
트랙백
댓글
글
표본이 정규분포(정규성)인지 여부를 어떻게 알 수 있는가?
표본의 정규분포를 확인하는 방법은 다양하다. 히스토그램과 같은 도표를 보고 추정할 수도 있고, 왜도와 첨도, 또는 정규성 검정을 통해 확인할 수도 있다.
정규성 검정은 표본의 크기에 따라 두 가지로 나뉜다.
첫째, n≥50이면, Kolmogorov-Smirnov(콜모고로프-스미르노프) 검정(ks test)을 통해 확인한다.
둘째, n<50이면, Shapiro-Wilk(샤피로-윌크) 검정을 통해 확인할 수 있다.
검정 결과 p>.05이면, 정규성을 가정한다. 다만 이 두 검정은 매우 엄밀한 검정으로 정규성을 가정하는 경우를 확보하는 것이 쉽지 않다.
이에 조금 더 유연한 방법이 왜도와 첨도를 확인하는 방법이다. 이와 관련해서는 Kline(클라인)의 책 "Principles and Practice of Structural Equation Modeling(2016)". 4판, 76-77페이지를 살펴보자.
그는 정규성을 확인함에 있어 왜도와 첨도의 절댓값의 해석을 대안으로 제시한다. 하지만 이와 관련하여 명확한 표준이 없으며, Nevitt & Hancock(2000)을 인용하면서 계산을 기반으로 일부의 지침이 제공될 수 있다고 하였다. 즉, 왜도의 절대값이 3보다 크면(|SI| > 3.0) 심각하게 기울어져 있음을 말하고, 첨도에 대해서는 합의가 아직 덜 이루어졌지만 그 절댓값이 8.0~20.0 사이(8.0 < |KI| < 20.0)면 심각한 첨도를 나타낸다고 보았다. 그리고 |왜도|≤3.0 이고, |첨도|≤10.0 이면, 그 분포가 “심각하게 정규성을 훼손하는 것은 아니다”고 결론내린다.
따라서 우리는 |왜도|≤3.0 이고, |첨도|≤8.0 이면, 정규분포라고 가정하고 분석을 진행해도 괜찮을 듯하다.
한편 West 등(1995)의 논문 "Structural Equation Models With Nonnormal Variables: Problems and Remedies(1995)", 74페이지를 보면, 정규분포를 따르지 않아 다른 분석방법을 사용해야하는 기준의 예로 200개 미만의 소표본인 경우 skewness(왜도) = 2 ; kurtosis(첨도) = 7을 언급하고 있다. 이를 근거로 기준값보다 적으면 정규성을 가정해도 좋다고 해석한다.
마지막으로 왜도(SI, Skew Index)와 첨도(KI, Kutosis Index)를 표준오차(s=σ/√n)와의 곱을 통해 상한/하한값을 구하고 그 값이 0을 포함하면 정규성을 가정한다고 보는 방법이다.
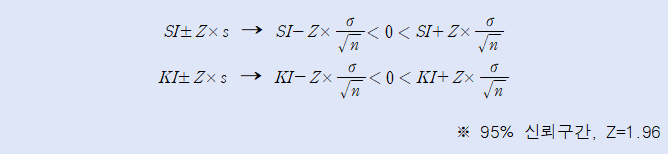
데이터분석을 실시하기에 앞서 표본의 정규성을 먼저 확인하는 것이 전제되어야 모수통계 검정을 실시할지 비모수통계 검정을 실시할지를 결정하게 된다.
한편 중심극한정리(central limit theorem, CLT)를 예로 들어 표본의 수(n)가 30 이상이면 정규성을 가정한다는 주장이 있는데, 이는 틀린 표현이다. 중심극한정리는 ‘표본집단’의 수가 증가함에 따라 모집단의 분포가 정규분포에 근접해 가는 현상을 말한다. 즉 표본집단의 수가 판단의 기준이다. 표본의 수를 말하는 것이 아닌데, 이를 오해해 잘못 전하는 경우가 있어 주의가 필요하다.
n≥30이라고, 정규성을 가정하는 것은 아니다.
'[楞嚴] 생각 나누기 > [平] 사회조사와 데이터분석' 카테고리의 다른 글
| 리커트(Likert) 척도는 서열척도인가? (0) | 2023.11.01 |
|---|---|
| 측도와 척도 (0) | 2023.11.01 |
| 평균 추론에 필요한 조건 (0) | 2023.11.01 |
| 왜 유의확률(p value)은 0.05를 기준으로 하는가? (0) | 2023.11.01 |
| p value(유의확률)를 표기하는 방법 (0) | 2023.11.01 |
설정
트랙백
댓글
글
평균 추론에 필요한 조건
통계에 대해 공부하다보면, 헷갈리는 것 중의 하나가 모집단에 사용되는 기호와 표본집단에 사용되는 기호가 혼재해서 사용된다는 점이다. 바로 평균과 표준편차에 대한 것이 그것이다.

일반적으로 모집단의 평균과 표준편차보다는 표본집단의 평균과 표준편차에 대해 확인하는 것이 훨씬 쉽다. 그리고 당연히 이 표본이 모집단을 대표할 수 있다는 확신을 전제한다. (물론 아닌 경우도 분명 있다.)
평균 추론에 대한 필요조건을 충족했을 때, 우리는 표본이 모집단을 대표할 수 있다고 보고 이때 모표준편차 σ는 표본표준편차 s로 대체할 수 있다. 그리고 그 조건은 다음과 같다.
첫째, 임의성이다. 표본은 무작위로 추출되어야 한다.
둘째, 일반성이다. 표본분포는 정규분포를 따라야 한다. 왜도의 절댓값이 2보다 작고, 첨도의 절댓값이 7보다 작을 때 정규성을 가정한다.
셋째, 독립성이다. 각각의 관측값은 독립이어야 한다. 표본의 수는 모집단의 수의 10% 이하로 관측값을 제거해도 모집단에 영향을 미치지 않아야 한다.

'[楞嚴] 생각 나누기 > [平] 사회조사와 데이터분석' 카테고리의 다른 글
| 측도와 척도 (0) | 2023.11.01 |
|---|---|
| 표본이 정규분포(정규성)인지 여부를 어떻게 알 수 있는가? (1) | 2023.11.01 |
| 왜 유의확률(p value)은 0.05를 기준으로 하는가? (0) | 2023.11.01 |
| p value(유의확률)를 표기하는 방법 (0) | 2023.11.01 |
| 부등식의 표현 이해 (0) | 2023.11.01 |
설정
트랙백
댓글
글
왜 유의확률(p value)은 0.05를 기준으로 하는가?
이 0.05라는 값은 통계적 유의미성을 지지하는 기준값이다. 즉 p<.05이면, 영가설 기각이 통계적으로 유의미하다는 뜻이 된다. 하지만 의문이 들지 않는가? 왜 하필 0.05일까? 만일 내가 한 연구에서 유의확률이 0.051이 나왔다면 좀 아깝지 않을까? p-hacking, p 해킹에 대해 더 찾아 읽어보자.
사실 이 0.05라는 값은 반드시 0.05이어야 할 과학적 근거가 있는 것은 아니다. 다만, 20세기 위대한 통계학자 중의 한명인 Ronald Fisher가 1925년 그의 저서 『Statistical Methods for Research Workers(p.46)』에서 처음 언급하게 된다.
[출처] 위키피디아 https://en.wikipedia.org/wiki/Ronald_Fisher
"The value for which P = 0.05, or 1 in 20, is 1.96 or nearly 2 ; it is convenient to take this point as a limit in judging whether a deviation is to be considered significant or not."
"P = 0.05, 즉 20분의 1인 값은 1.96 또는 거의 2입니다. 편차가 중요한지 여부를 판단할 때 이 점을 한계로 삼는 것이 편리합니다."
귀납법이 갖는 철학적 한계를 해결하기 위해 통계적 접근방법을 활용한 것으로, 현대 통계의 역사를 다룬 『The Lady Tasting Tea: How Statistics Revolutionized Science in the 20th Century』에서 David Salsburg(2001)는 Fisher의 결정이 ‘임의적’인 것이었다고 말한다.
p<.05는 관행일 뿐 절대시할 수치는 아니라 할 것이지만, 사회적 약속인 것 또한 사실이다.
'[楞嚴] 생각 나누기 > [平] 사회조사와 데이터분석' 카테고리의 다른 글
| 표본이 정규분포(정규성)인지 여부를 어떻게 알 수 있는가? (1) | 2023.11.01 |
|---|---|
| 평균 추론에 필요한 조건 (0) | 2023.11.01 |
| p value(유의확률)를 표기하는 방법 (0) | 2023.11.01 |
| 부등식의 표현 이해 (0) | 2023.11.01 |
| 공(空)과 무(無), 0과 null (0) | 2023.11.01 |

RECENT COMMENT